
Natural Parameters EStimation (NPES) вокодер
Данная технология цифрового представления (кодирования) речи
основана на математической модели речеобразования. В рамках этой модели, речевой сигнал
описывается набором параметров, значения которых изменяются во времени и характеризуют
состояние элементов голосового аппарата человека при произнесении звуков речи. В связи
с тем, что состояние голосового тракта при артикуляции изменяется сравнительно
медленно во времени, параметры модели можно считать локально-постоянными на участках
(сегментах) речевого сигнала длительностью 15-20 миллисекунд. Более того, множество
различных звуков речи конечно, поэтому всё пространство параметров можно аппроксимировать
конечным числом значений, сопоставив каждому сегменту речевого сигнала некоторое число (код).
Такой способ цифрового представления речи позволяет в десятки раз сократить объём информации,
требуемой для её передачи и хранения. Кроме того, физическая обусловленность и полнота параметров позволяет
использовать данную технологию в задачах идентификации диктора, распознавания и синтеза речи.
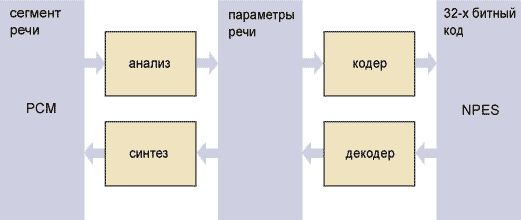
Структура вокодера
Функционально NPES вокодер состоит из четырёх частей, каждая из которых осуществляет преобразование цифрового представления (формата) речевого сигнала. Процедура анализа преобразует сегмент речевого сигнала из представления в виде последовательности отсчётов (формат PCM) в представление в виде значений параметров модели, а процедура синтеза осуществляет обратное преобразование. Процедура кодирования позволяет сопоставить каждому набору значений параметров определённое 32-х битное число (формат NPES), а процедура декодирования производит обратное действие.
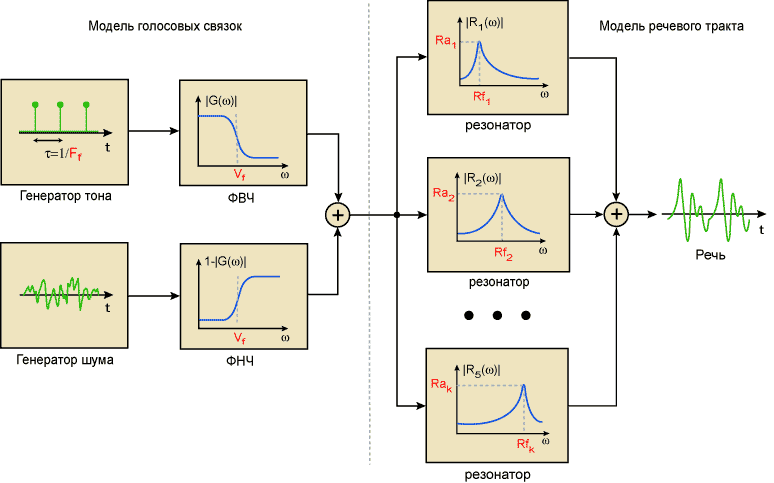
Модель речеобразования
В основе NPES вокодера лежит модель речеобразования, которая состоит из двух независимых частей. Одна из них описывает работу голосовых связок, а другая - работу органов артикуляции. Параметрами модели голосовых связок являются частоты основного тона и вокализованности ( Ff,Vf ). Частота основного тона определяет частоту колебаний голосовых связок при произнесении вокализованных звуков ( [a], [o] ). Частота вокализованности определяет долю стохастической компоненты при произнесении частично вокализованных и невокализованных звуков ( [s], [h], [z] ). Параметрами модели органов артикуляции являются частоты и амплитуды резонаторов ( Rak, Rfk ), которые выбираются таким образом, чтобы амплитудно-частотная характеристика модели наиболее точно соответствовала формантной структуре речевого сигнала.
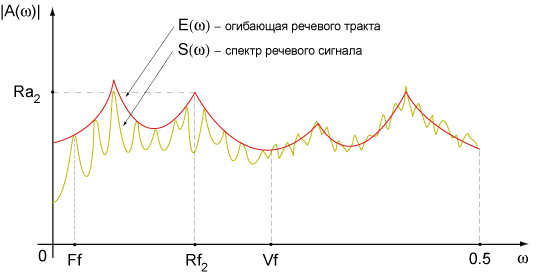
Значения параметров модели могут быть легко найдены по кратковременному спектру речевого сигнала, что упрощает их визуализацию и позволяет изучать их поведения при помощи широко распространённых программ для обработки звука.
Сжатие речи
Основной областью применения NPES вокодера являются телекоммуникации. Требуемая пропускная способность канала для передачи кодированного речевого сигнала в реальном масштабе времени является основной его характеристикой. Обычно эта величина выражается в BPS (Bits Per Second). NPES вокодер позволяет изменять размер сегмента анализа/синтеза или количество сегментов в секунду (SPS), тем самым изменяя требуемую скорость передачи (BPS = SPS * 32). Следующая таблица содержит оценки качества кодирования речи в зависимости от пропускной способности канала.
|
Исходный сигнал
|
Скорость передачи (BPS)
|
Качество речи (MOS)
|
| Мужской голос | 1280 | 3.28 |
| 1600 | 3.44 | |
| 2000 | 3.48 | |
| Женский голос | 1280 | 3.34 |
| 1600 | 3.45 | |
| 2000 | 3.53 |
- Качество речи измерялось в соответствии с рекомендацией ITU-T P.861
- Задержка обработки для всех скоростей передачи - 25 миллисекунд.
- Все сигналы оцифрованы с частотой дискретизации 8 КГц и разрядностью 16 бит.
Преобразование речи
Благодаря тому, что параметры математической модели, лежащей в основе NPES вокодера, соответствуют физическим характеристикам элементов голосового аппарата, их значения, полученные для голоса диктора, могут быть легко изменены таким образом, чтобы соответствовать голосу другого диктора или другому способу произношения. Это важное свойство может иметь различные применения. Например, частота основного тона может быть установлена в соответствии с нотами музыки, что позволяет использовать NPES вокодер для караоке. В следующей таблице приведены примеры преобразования высоты голоса и размеров речевого тракта.
|
Исходный сигнал
|
Преобразованный сигнал
|
| Мужской голос | высота голоса: + 1 октава, размер тракта: 80 % |
| Женский голос | высота голоса: - 2 октавы, размер тракта: 120 % |
Требования к вычислительным ресурсам
В следующей таблице отражены требования процедур NPES вокодера к вычислительным ресурсам системы на процессоре Pentium III 800 MHz и операционной системой Windows XP.
Процедура |
Загрузка CPU (%) |
RAM (Kб) |
ROM (Кб) |
анализ |
12 |
270 |
30 |
синтез |
5 |
25 |
15 |
анализ+синтез |
17 |
280 |
35 |
анализ+кодер |
15 |
271 |
155 |
синтез+декодер |
5 |
26 |
145 |
анализ+синтез+кодер+декодер |
20 |
282 |
165 |
- Под загрузкой CPU подразумевается требуемая доля всех вычислительных ресурсов системы для выполнения процесса в реальном масштабе времени. Она зависит от частоты дискретизации и характеристик речевого сигнала. В таблице указаны усреднённые значения, полученные при помощи утилит командной строки из NPES SDK.
- Размер RAM определяет объём памяти, требуемой для переменных и стека.
- Размер ROM определяет объём памяти, требуемой для данных и программы.
технологии | программы | статьи | ссылки | о нас | NPES вокодер | NPES SDK | ADSS фильтр | ADSS SDK | Fork | VoiceVary | SoundClear | P861 | P56 |
© Phrase Research Group, 2002 © Phrase-Art, 2002